Tutorial - llamaspeak
Talk live with Llama using streaming ASR/TTS, and chat about images with Llava!

-
The
NanoLLMlibrary provides optimized inference for LLM and speech models. - It's recommended to run JetPack 6.0 to be able to run the latest containers.
The
WebChat
agent has responsive conversational abilities and multimodal support for chatting about images with vision/language models, including overlapping ASR/LLM/TTS generation and verbal interruptability.
Running llamaspeak
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB)
-
Running one of the following versions of JetPack :
JetPack 6 (L4T r36)
-
NVMe SSD highly recommended for storage speed and space
-
22GBfornano_llmcontainer image -
Space for models (
>10GB)
-
-
Start the Riva server first and test the ASR examples.
jetson-containers run --env HUGGINGFACE_TOKEN=hf_xyz123abc456 \
$(autotag nano_llm) \
python3 -m nano_llm.agents.web_chat --api=mlc \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--asr=riva --tts=piper
This will start llamaspeak with text LLM and ASR/TTS enabled. You can then navigate your browser to
https://IP_ADDRESS:8050
--web-port
(and
--ws-port
for the websocket port)
The
code
and
docs
for the
WebAgent
that runs llamaspeak can be found in the NanoLLM library. This block diagram shows the speech pipeline with interleaved model generation, user interruption, and streaming I/O:
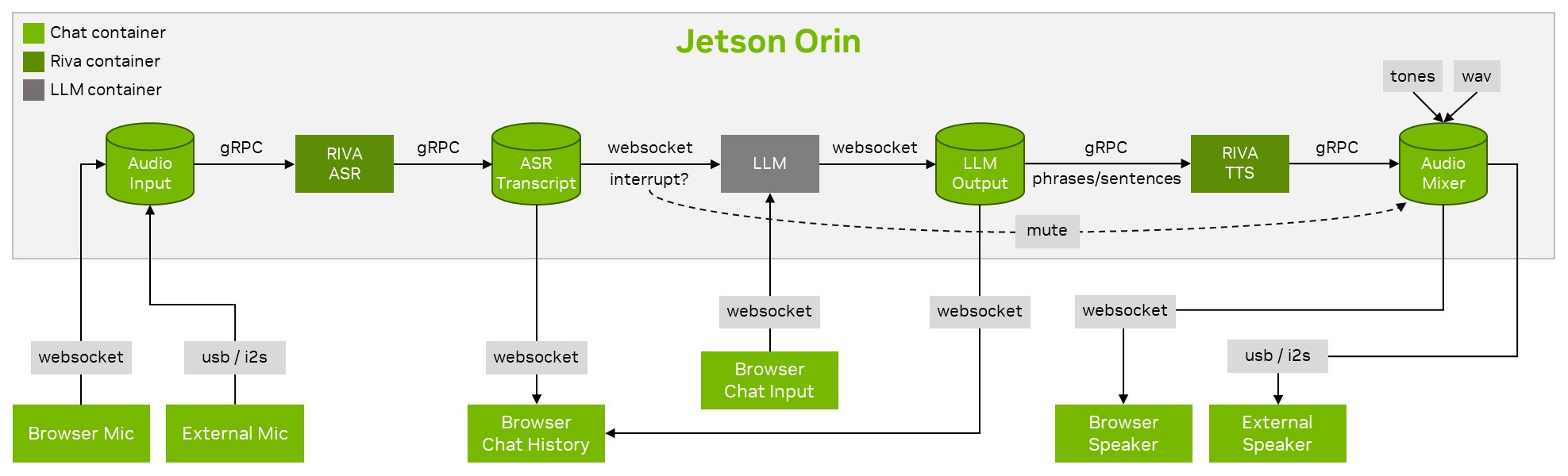
Multimodality
If you load a multimodal vision/language model instead, you can drag images into the chat and ask questions about them:
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.agents.web_chat --api=mlc \
--model Efficient-Large-Model/VILA-7b \
--asr=riva --tts=piper
For more info about the supported vision/language models, see the NanoVLM page.
Function Calling
There's the ability to define functions from Python that the bot has access to and can invoke based on the chat flow:
This works by using the
bot_function()
decorator and adding the API description's to the system prompt:
from nano_llm import NanoLLM, ChatHistory, BotFunctions, bot_function
from datetime import datetime
@bot_function
def DATE():
""" Returns the current date. """
return datetime.now().strftime("%A, %B %-m %Y")
@bot_function
def TIME():
""" Returns the current time. """
return datetime.now().strftime("%-I:%M %p")
system_prompt = "You are a helpful and friendly AI assistant." + BotFunctions.generate_docs()
The system prompt can be autogenerated from the Python docstrings embedded in the functions themselves, and can include parameters that the bot can supply (for example, selectively saving relevant user info to a vector database for RAG like is shown in the video).
For more information about this topic, see the Function Calling section of the NanoLLM documentation.