Tutorial - LLaVA
LLaVA is a popular multimodal vision/language model that you can run locally on Jetson to answer questions about image prompts and queries. Llava uses the CLIP vision encoder to transform images into the same embedding space as its LLM (which is the same as Llama architecture). Below we cover different methods to run Llava on Jetson, with increasingly optimized performance:
-
Chat with Llava using
text-generation-webui -
Run from the terminal with
llava.serve.cli -
Quantized GGUF models with
llama.cpp -
Optimized Multimodal Pipeline with
NanoVLM
| Llava-13B (Jetson AGX Orin) | Quantization | Tokens/sec | Memory |
|---|---|---|---|
text-generation-webui
|
4-bit (GPTQ) | 2.3 | 9.7 GB |
llava.serve.cli
|
FP16 (None) | 4.2 | 27.7 GB |
llama.cpp
|
4-bit (Q4_K) | 10.1 | 9.2 GB |
NanoVLM
|
4-bit (MLC) | 21.1 | 8.7 GB |
In addition to Llava, the
NanoVLM
pipeline supports
VILA
and mini vision models that run on Orin Nano as well.

1. Chat with Llava using
text-generation-webui
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB)
-
Running one of the following versions of JetPack :
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
-
NVMe SSD highly recommended for storage speed and space
-
6.2GBfortext-generation-webuicontainer image -
Space for models
-
CLIP model :
1.7GB -
Llava-v1.5-13B-GPTQ model :
7.25GB
-
CLIP model :
-
-
Clone and setup
jetson-containers:git clone https://github.com/dusty-nv/jetson-containers bash jetson-containers/install.sh
Download Model
jetson-containers run --workdir=/opt/text-generation-webui $(autotag text-generation-webui) \
python3 download-model.py --output=/data/models/text-generation-webui \
TheBloke/llava-v1.5-13B-GPTQ
Start Web UI with Multimodal Extension
jetson-containers run --workdir=/opt/text-generation-webui $(autotag text-generation-webui) \
python3 server.py --listen \
--model-dir /data/models/text-generation-webui \
--model TheBloke_llava-v1.5-13B-GPTQ \
--multimodal-pipeline llava-v1.5-13b \
--loader autogptq \
--disable_exllama \
--verbose
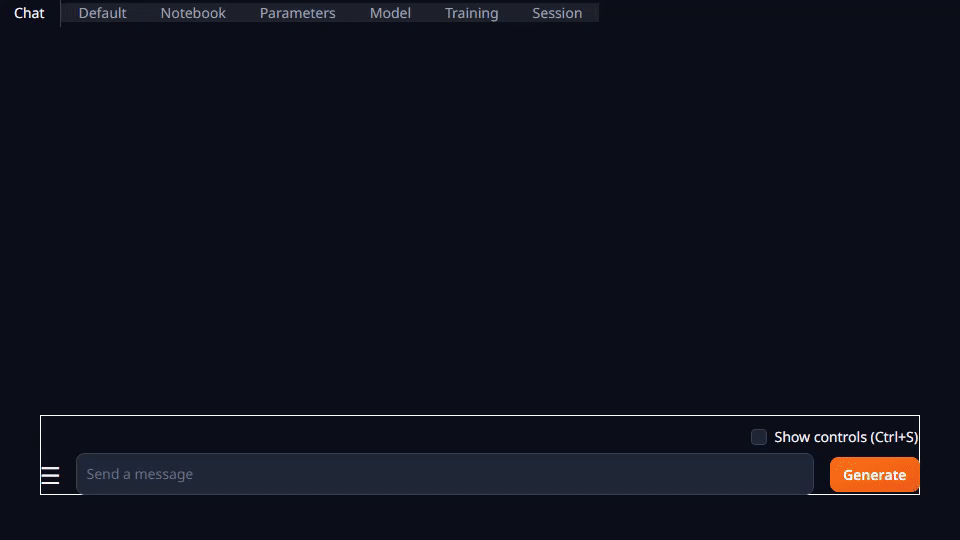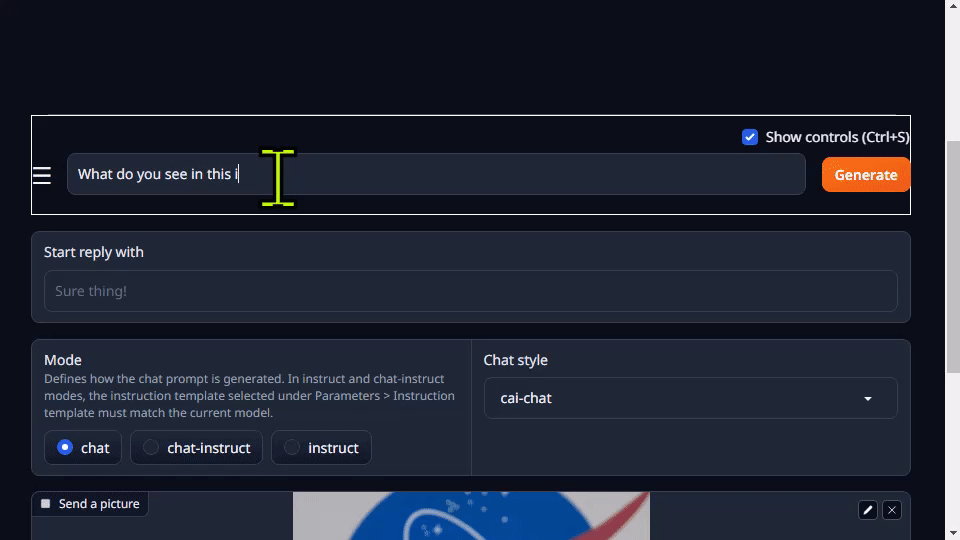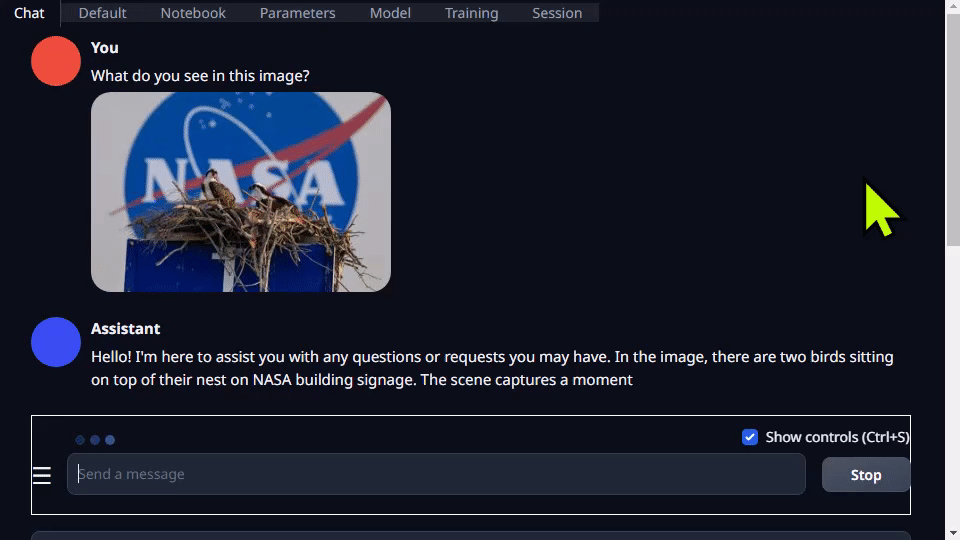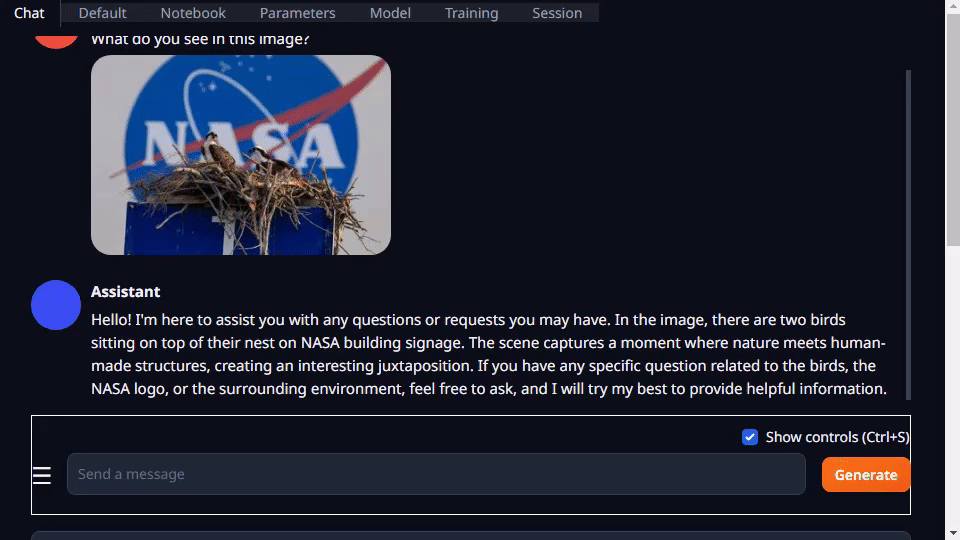
Go to Chat tab, drag and drop an image into the Drop Image Here area, and your question in the text area and hit Generate :
Result

2. Run from the terminal with
llava.serve.cli
What you need
-
One of the following Jetson:
Jetson AGX Orin 64GB Jetson AGX Orin (32GB)
-
Running one of the following versions of JetPack :
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
-
NVMe SSD highly recommended for storage speed and space
-
6.1GBforllavacontainer -
14GBfor Llava-7B (or26GBfor Llava-13B)
-
This example uses the upstream Llava repo to run the original, unquantized Llava models from the command-line. It uses more memory due to using FP16 precision, and is provided mostly as a reference for debugging. See the Llava container readme for more info.
llava-v1.5-7b
jetson-containers run $(autotag llava) \
python3 -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file /data/images/hoover.jpg
llava-v1.5-13b
jetson-containers run $(autotag llava) \
python3 -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-13b \
--image-file /data/images/hoover.jpg
Unquantized 13B may run only on Jetson AGX Orin 64GB due to memory requirements.
3. Quantized GGUF models with
llama.cpp
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB)
-
Running one of the following versions of JetPack :
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
llama.cpp is one of the faster LLM API's, and can apply a variety of quantization methods to Llava to reduce its memory usage and runtime. Despite its name, it uses CUDA. There are pre-quantized versions of Llava-1.5 available in GGUF format for 4-bit and 5-bit:
jetson-containers run --workdir=/opt/llama.cpp/bin $(autotag llama_cpp:gguf) \
/bin/bash -c './llava-cli \
--model $(huggingface-downloader mys/ggml_llava-v1.5-13b/ggml-model-q4_k.gguf) \
--mmproj $(huggingface-downloader mys/ggml_llava-v1.5-13b/mmproj-model-f16.gguf) \
--n-gpu-layers 999 \
--image /data/images/hoover.jpg \
--prompt "What does the sign say"'
| Quantization | Bits | Response | Tokens/sec | Memory |
|---|---|---|---|---|
Q4_K
|
4 | The sign says "Hoover Dam, Exit 9." | 10.17 | 9.2 GB |
Q5_K
|
5 | The sign says "Hoover Dam exit 9." | 9.73 | 10.4 GB |
A lower temperature like 0.1 is recommended for better quality (
--temp 0.1
), and if you omit
--prompt
it will describe the image:
jetson-containers run --workdir=/opt/llama.cpp/bin $(autotag llama_cpp:gguf) \
/bin/bash -c './llava-cli \
--model $(huggingface-downloader mys/ggml_llava-v1.5-13b/ggml-model-q4_k.gguf) \
--mmproj $(huggingface-downloader mys/ggml_llava-v1.5-13b/mmproj-model-f16.gguf) \
--n-gpu-layers 999 \
--image /data/images/lake.jpg'
In this image, a small wooden pier extends out into a calm lake, surrounded by tall trees and mountains. The pier seems to be the only access point to the lake. The serene scene includes a few boats scattered across the water, with one near the pier and the others further away. The overall atmosphere suggests a peaceful and tranquil setting, perfect for relaxation and enjoying nature.
You can put your own images in the mounted
jetson-containers/data
directory. The C++ code for llava-cli can be found
here
. The llama-cpp-python bindings also
support Llava
, however they are slower from Python (potentially handling of the tokens)
4. Optimized Multimodal Pipeline with
NanoVLM
What's Next
This section got too long and was moved to the NanoVLM page - check it out there for performance optimizations, mini VLMs, and live streaming!

