Tutorial - Whisper
Let's run OpenAI's Whisper , pre-trained model for automatic speech recognition on Jetson!
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)
-
Running one of the following versions of JetPack :
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
-
NVMe SSD highly recommended for storage speed and space
-
6.1 GBforwhispercontainer image - Space for checkpoints
-
-
Clone and setup
jetson-containers:git clone https://github.com/dusty-nv/jetson-containers bash jetson-containers/install.sh
How to start
Use
run.sh
and
autotag
script to automatically pull or build a compatible container image.
jetson-containers run $(autotag whisper)
The container has a default run command (
CMD
) that will automatically start the Jupyter Lab server, with SSL enabled.
Open your browser and access
https://<IP_ADDRESS>:8888
.
Attention
Note it is
https
(not
http
).
HTTPS (SSL) connection is needed to allow
ipywebrtc
widget to have access to your microphone (for
record-and-transcribe.ipynb
).
You will see a warning message like this.
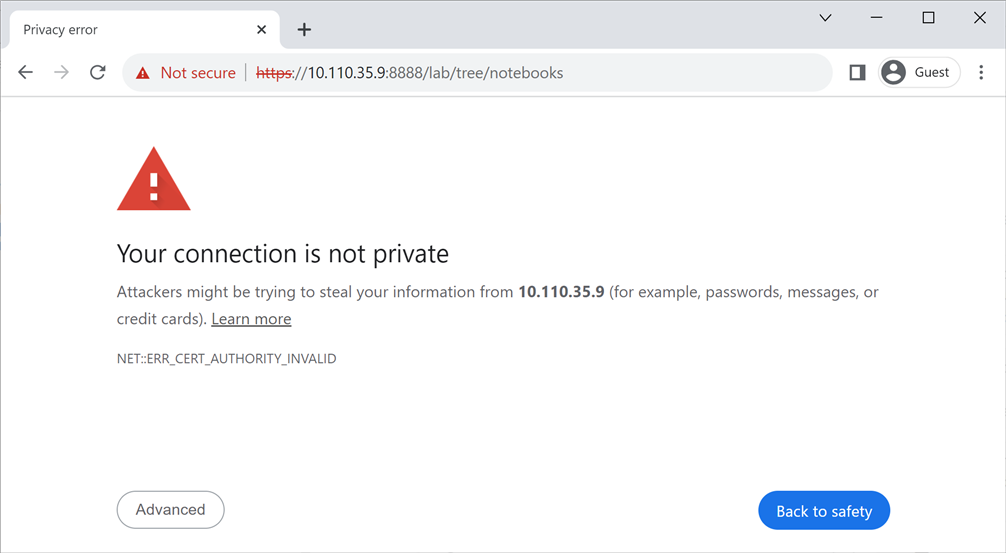
Press "
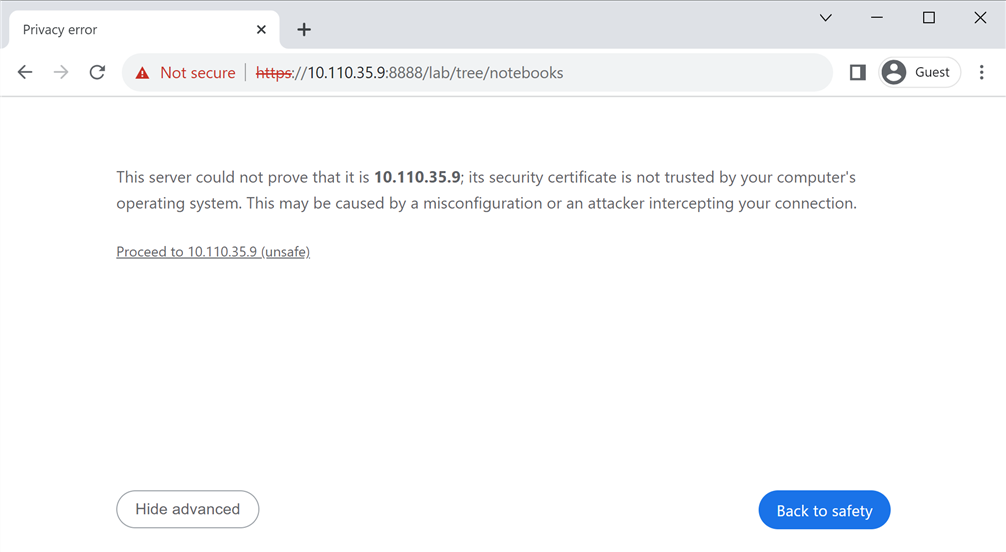
Advanced
" button and then click on "
Proceed to
The default password for Jupyter Lab is
nvidia.
Run Jupyter notebooks
Whisper repo comes with demo Jupyter notebooks, which you can find under
/notebooks/
directory.
jetson-containers
also adds one convenient notebook (
record-and-transcribe.ipynb
) to record your audio sample on Jupyter notebook in order to run transcribe on your recorded audio.
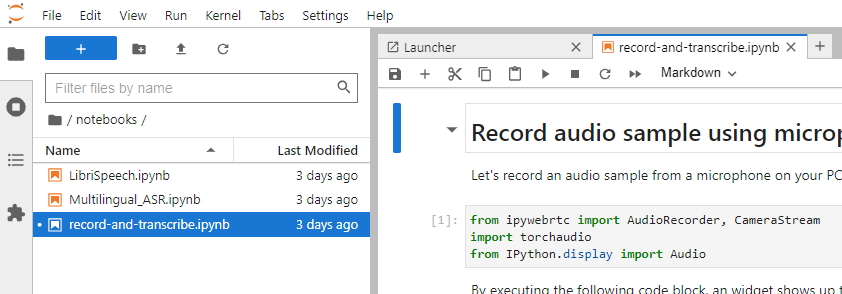
record-and-transcribe.ipynb
This notebook is to let you record your own audio sample using your PC's microphone and apply Whisper's
medium
model to transcribe the audio sample.
It uses Jupyter notebook/lab's
ipywebrtc
extension to record an audio sample on your web browser.
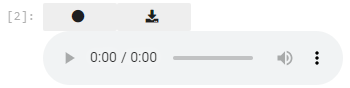
Attention
When you click the ⏺ botton, your web browser may show a pop-up to ask you to allow it to use your microphone. Be sure to allow the access.
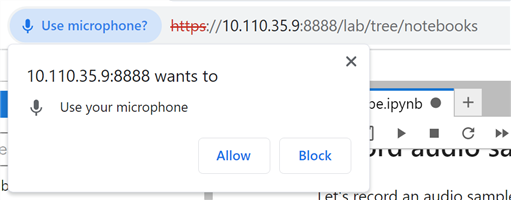
Final check
Once done, if you click on the " ⚠ Not secure " part in the URL bar, you should see something like this.
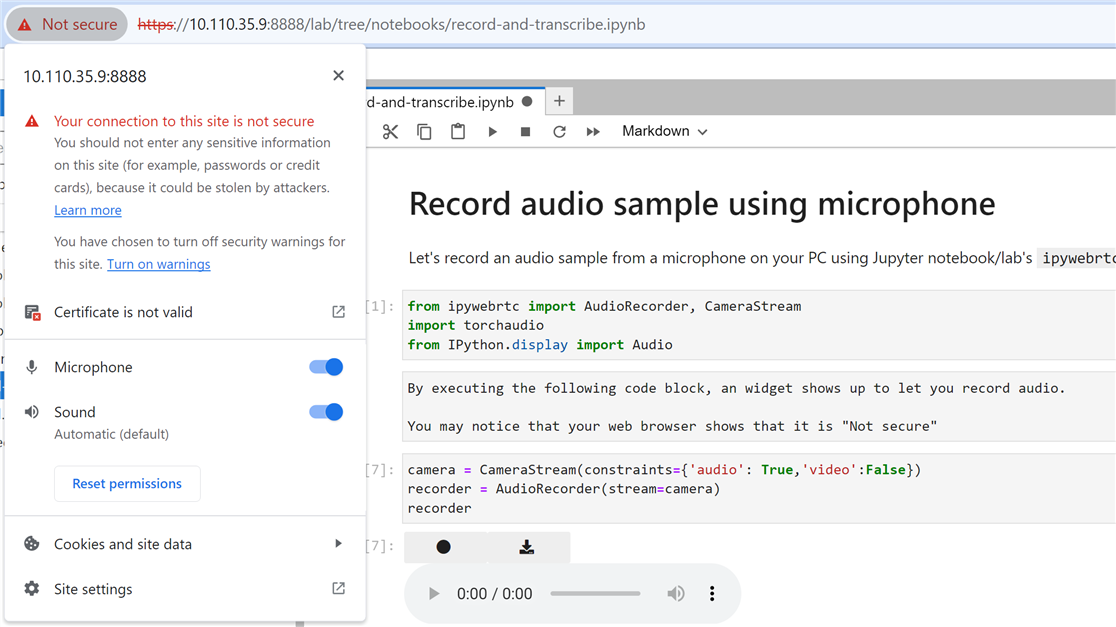
Result
Once you go through all the steps, you should see the transcribe result in text like this.
![]()